01 Cat vs Dog Recognition
Introduction: Manually building LeNet for cat vs dog recognition.
Reference: https://mtyjkh.blog.csdn.net/article/details/121263237 Code: 01-cat-dog (github.com)
Note: Beginners are advised to practice typing all the code, as it serves as a template. Regardless, you should be able to type it fluently (know the steps, the core of each step, how to do it, which functions are involved, how to connect them, etc.). It's okay if you don't understand initially; just practice multiple times. While typing, you can think about why things are done this way, but for fundamental aspects, don't insist on investigating the reason; memorize them first, just like learning arithmetic requires memorizing the multiplication table. Later, you will deeply understand why. You must practice!
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor, Lambda, Compose
import matplotlib.pyplot as plt
import torchvision.transforms as transforms
import numpy as np
1. Data Loading and Preprocessing
train_data_dir = '/content/1-cat-dog'
test_data_dir = '/content/1-cat-dog'
train_transforms = transforms.Compose([
transforms.Resize([224, 224]),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
test_transforms = transforms.Compose([
transforms.Resize([224, 224]),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
train_dataset = datasets.ImageFolder(train_data_dir, transform=train_transforms)
test_dataset = datasets.ImageFolder(test_data_dir, transform=test_transforms)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=4, shuffle=True, num_workers=1)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=4, shuffle=True, num_workers=1)
# Check data shape
for X, y in test_loader:
print("Shape of X [N, C, H, W]:", X.shape)
print("Shape of y:", y.shape, y.dtype)
break
Data processing steps: Preprocess data - Read data - Wrap data
transforms.Composedatasets.ImageFoldertorch.utils.data.DataLoader
Questions:
-
What does
transforms.ToTensor()do?- Normalizes data to [0,1] by dividing by 255.
- Changes HWC to CHW (format: (height, width, channels), pixel order RGB).
-
How are the mean and std in
transforms.Normalize()determined?- The values [0.485, 0.456, 0.406] are computed from the ImageNet training set.
-
Why apply normalization after normalization?
Normalize()subtracts mean and divides by std per channnel. Data in (0,1) may cause large bias inputs (b) while model initializes with b=0, slowing convergence. AfterNormalize, data is in [-1,1], speeding up convergence. Although ToTensor changes range to [0,1], it doesn't change the distribution; Normalize makes it more Gaussian-like.
2. Define the Model
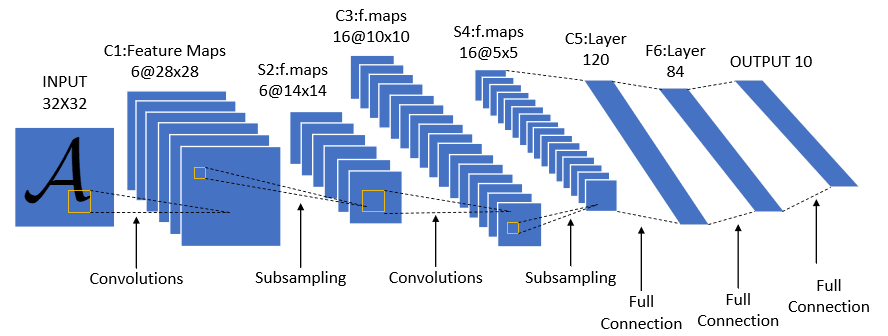
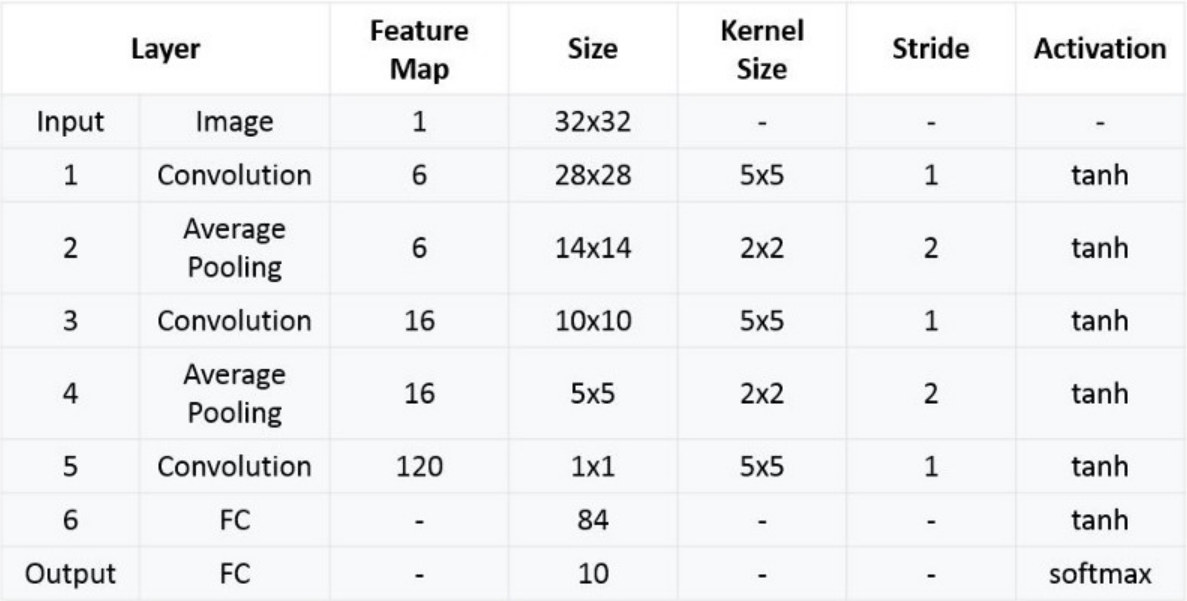
import torch.nn.functional as F
# Device
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using {device} device")
# Model definition
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
# Conv2d: input channels, output channels, kernel size
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 53 * 53, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 2)
def forward(self, x):
x = F.relu(self.conv1(x))
x = self.pool(x)
x = F.relu(self.conv2(x))
x = self.pool(x)
x = x.view(-1, 16 * 53 * 53) # Flatten for fully connected layers
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
model = LeNet().to(device)
print(model)
Why fc1 input size is 16 * 53 * 53?
- 16 is the number of channels.
- Convolution formula:
output_size = (input_size + 2*padding - kernel_size) / stride + 1 - conv1: (224 + 0 - 5)/1 + 1 = 220
- pool1: (220 + 0 - 2)/2 + 1 = 110
- conv2: (110 + 0 - 5)/1 + 1 = 106
- pool2: (106 + 0 - 2)/2 + 1 = 53
- Hence, 16 channels * 53 * 53.
3. Define Loss Function and Optimizer
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)
4. Define Training Function
def train(dataloader, model, loss_fn, optimizer):
dataset_size = len(dataloader.dataset)
model.train()
for batch, (X, y) in enumerate(dataloader):
X, y = X.to(device), y.to(device)
# Compute prediction error
pred = model(X)
loss = loss_fn(pred, y)
# Backpropagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch % 100 == 0:
loss_val, current = loss.item(), batch * len(X)
print(f"loss: {loss_val:>7f} [{current:>5d}/{dataset_size:>5d}]")
What does the training function need?
- Data:
dataloader - Model:
model - Loss function:
loss_fn - Optimizer:
optimizer
How is the label y determined?
- It is determined when wrapping data with
torch.util.data.DataLoader.
What does model.train() do?
- Sets the model to training mode, enabling certain layers like Dropout and BatchNorm to behave differently (e.g., Dropout randomly deactivates neurons to prevent overfitting; BatchNorm uses batch statistics).
5. Define Testing Function
def test(dataloader, model, loss_fn):
dataset_size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval()
test_loss, correct = 0, 0
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= dataset_size
print(f"Test Error:\n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f}\n")
What does the testing function need?
- Data:
dataloader - Model:
model - Loss function:
loss_fn
- No optimizer since no update.
What does model.eval() do?
- Sets the model to evaluation mode, ensuring deterministic behavior (e.g., Dropout is disabled; BatchNorm uses running statistics).
What does pred.argmax(1) == y mean?
argmax(1)returns the index of the maximum value along axis 1 (class prediction). The comparison checks if the predicted class equals the true label.
Core: Compute loss and accuracy.
6. Training Loop
epochs = 20
for epoch in range(epochs):
print(f"Epoch {epoch+1}\n----------------------------")
train(train_loader, model, loss_fn, optimizer)
test(test_loader, model, loss_fn)
print("Done!")